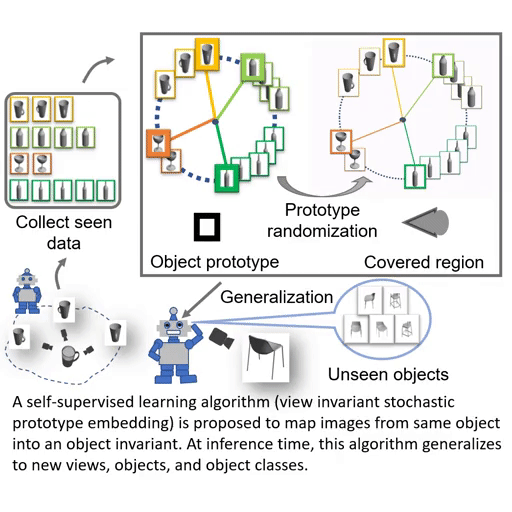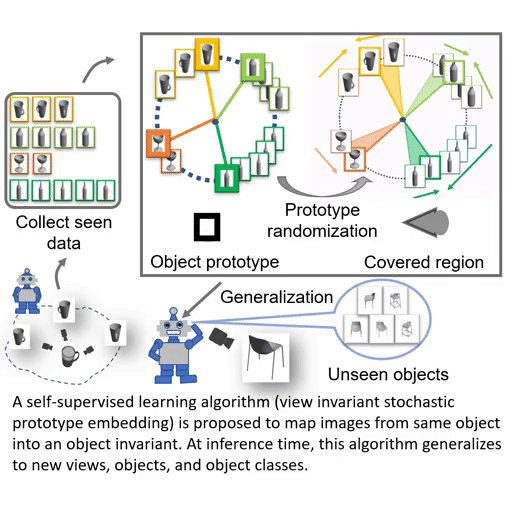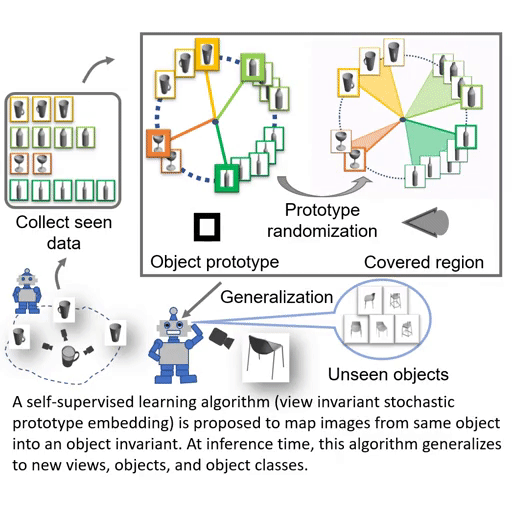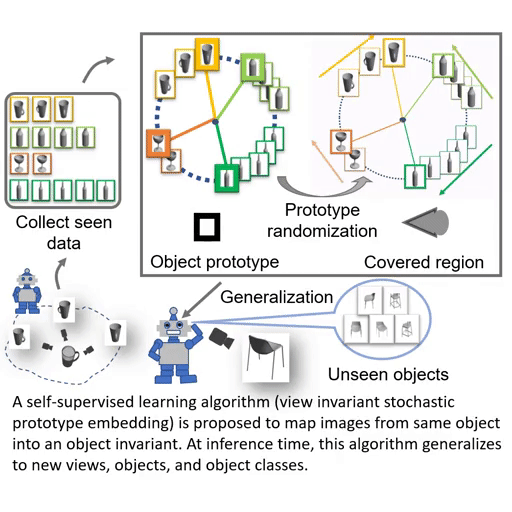






 Paper
Supplementary material
Poster
Slides
Paper
Supplementary material
Poster
Slides
 Code
Code
@InProceedings{Ho_2020_CVPR,
author = {Ho, Chih-Hui and Liu, Bo and Wu, Tz-Ying and Vasconcelos, Nuno},
title = {Exploit Clues From Views: Self-Supervised and Regularized Learning for Multiview Object Recognition},
booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}